(First created: 05/25/2024 |Personal Opinion)
I hate to make predictions but when a sharp guy ask you a question on the spot you have to make up something right? The question of “What’s your take on the scientific side of AI/ML practice in the age of LLMs?” lingered on my mind and triggered a bunch of thoughts and research.
The democratization and commoditization of AI/ML
The old way of doing AI/ML involves a vast system of different components, processes and talents of both great breadth and depth:
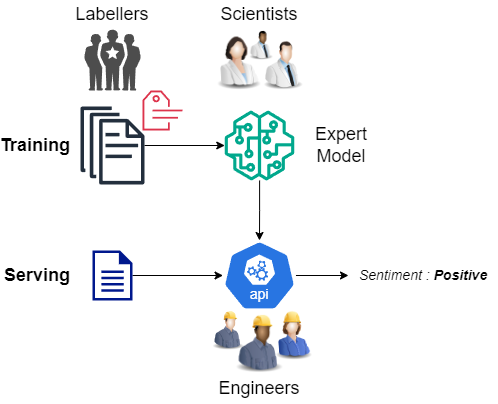
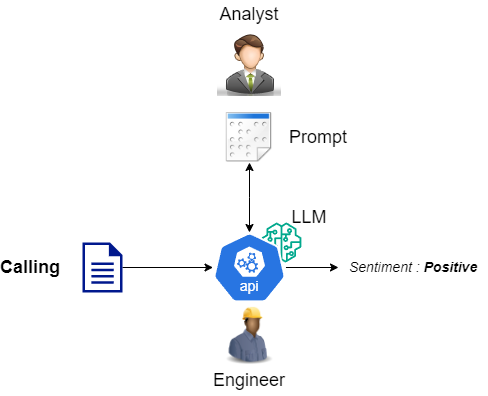
LLM disrupts it by:
- Replacing customly trained expert model with generally trained large language model (LLM)
- Replacing the army of laberlers and highly skilled scientits with domin experts
- Replacing specialized MLOps engineer with general DevOps engineer
Look Ma, there are no scientists in below picture!
As a result, the overall landscape of AI/ML practices shifts:
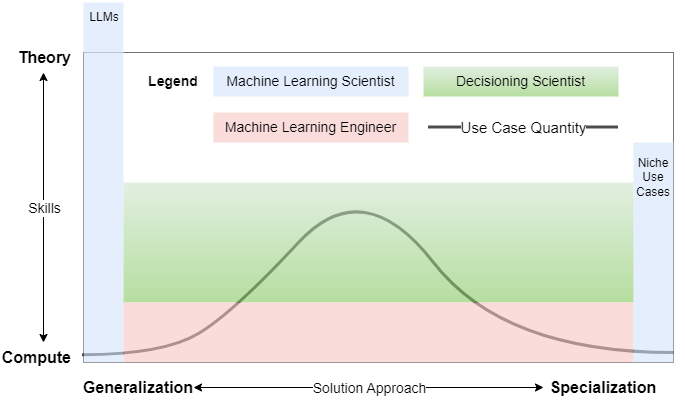
The rise of Machine Learning Engineer (MLE)
Machine learning engineers are software engineers with superficial or black box understandings of AI/ML. Their focus is on engineering the end-to-end system with AI/ML as components in it. Think ML engineering as specialized plumbing in the AI/ML domain.
The fall of Machine Learning Scientist (MLS)
The skill set[1] required to do true machine learning science has been highly specialized and at the same time the need for machine learning scientists will dwindle:
- On the left tail, after market consolidation, only a handful of LLM providers will need highly (over-the-roof) skilled AI/ML scientists. They rightfully deserve the million-dollar salary but there just won’t be many of these positions.
- On the right tail, only a small portion of the specialized use cases will need highly skilled AI/ML scientists.
The rest of us, those I call pretentious Hugging Face and LLM “scientists”, will lose our jobs to ML engineers. The bean counter’s logic is simple: If all you do is downloading models from Hugging Face, deploying them internally and claiming them yours, I can teach a fresh computer science graduate MLE to do it in one day. “But I’m fine-tuning the model with our proprietary data!”, still easy and cheaper to teach engineers to do it. Ditto for those ‘scientists’ who rely on LLMs to do their work. When AI/ML is reduced to API calls, any engineer can do it.
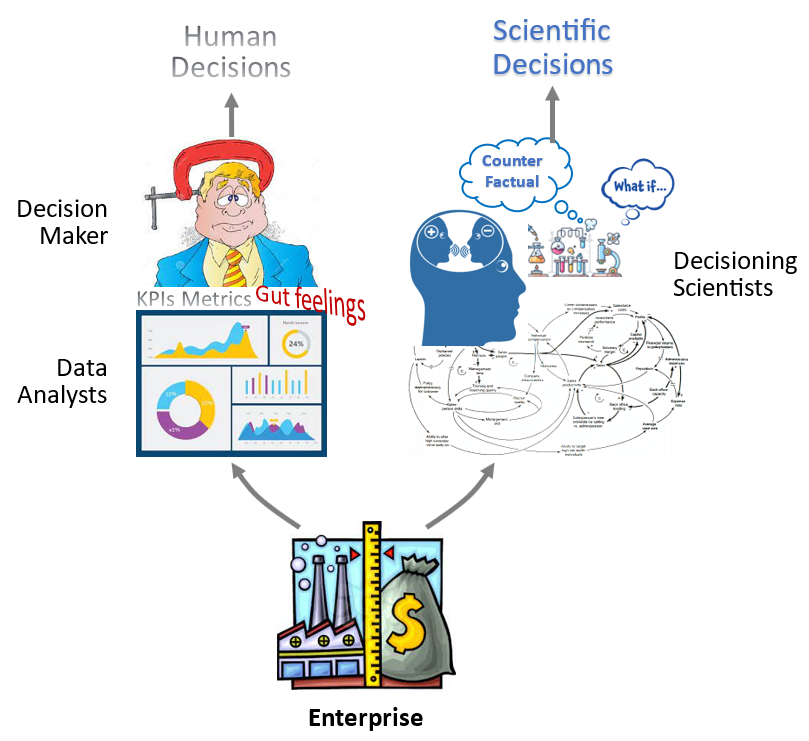
What will those Master/PhD level mathematically trained scientists do then? Well, they must find new and truly scientific things to do in the AI/ML value chain. I propose Decision Science with a tag line of “a new kind of DS”! (Please bear with my BS here 🙂
The rebirth of Decision Science
I earned a degree in Decision Science and one of the textbooks we used is “Making Hard Decisions” which was first published in 1991. Since then there were sporadic loner researchers here and there and books such as “The Book of Why” but the field never really take off. Biased as I am, I predict the time has finally come for decision science.
Causal Analytics
No matter how accurate, reliable and trustworthy AI/ML models get, what they produce are mere associations[2]. A dog picture associated to the label “dog”. A piece of text associated to the sentiment of “positive”… Association is about “seeing”, “observing”, “perceiving”.
Causality requires more physical and mental experimentations on top of associations. It’s about “doing”, “intervening” and “testing”.
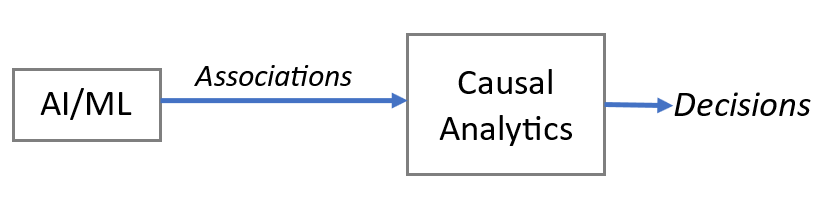
Decisions made out of causality is more scientific and more likely to deliver value, hence it’s higher up there on Judea Pearl’s ladder of causality:

The government takes the lead
You may not believe it but the government has been the only institution that practices causal analytics:
- The FDA. All the pills that we take everyday have been causally analyzed and proved to be efficacious and effective by Ph.D. level decisioning scientists (a.k.a. Statisticians).
- The Central Bank. Each of those rate cutting decisions are backed by causal time series analyses conducted by Ph.D. level decisioning scientist (a.k.a. Econometricians).
- The military-industrial complex (MIC). Anyone who worked in the defense industry would tell you that some rigorous causal analysis actually happened during the procurement process by some Master level decisioning scientists (a.k.a. System Engineers, Reliability Engineers) .
Then follow the enterprises
Enterprises are profit driven. When the fragile human decisions prove to be ineffective or the human brain fails to comprehend the sheer scale and complexities posed by modern day digitized enterprise, they’ll turn to causal analytics for scientific decisions, for both improved top and bottom lines.
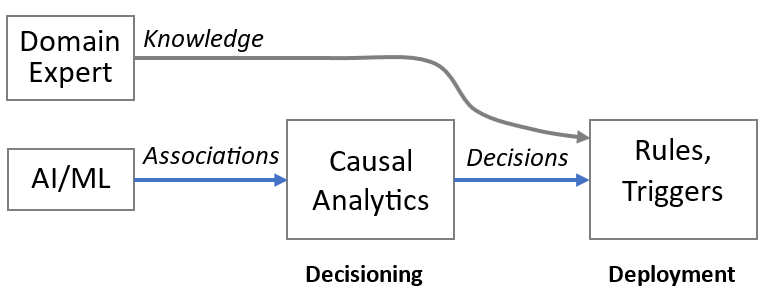
Rules are not science
Many equate decisioning with rules. That’s unfortunate:
- “IF… THEN…” rules are heuristics made up by human. They works but prone to human bias.
- Rules don’t scale, even with the help of RETE algorithm. Expert System, the poster child of symbolic AI based on rules, was actually one of the triggers of one of the AI Winters.
- Rules are brittle and hard to generalize. Even the slightest variation may render a predefined set of rules useless.
Truly scientific decisions more likely come out of ad hoc causal analytics on the specific data set generated by the use case. That’s what data driven decisions means.
However well-thought out formalized rules system such as business process management systems can be a good front end to visualize and implement the insights that come out of causal analytics. From this sense, causal analytics is “decisioning” – decisions being made and rules on the other hand are “decisions made“.
Ab Analytica Venit Decisio
I don’t know Latin. What I’m trying to say is “from analytics comes decision”. But why I try to say it in Latin? I guess that’s the vain side of me : )
I’ll leave you with a caution that is be careful with those who boast about “Causal AI“:
- They are either ignorant, about the fact that AI/ML produce only associations.
- Or they’re intentionally equivocating, between the “AI –> Causal Analytics” pipeline and AI.
- Or they’re just pushing the marketing BS.
Causal is the good old analytics, albeit spiraled to a higher level.
Causal References:
- Books: The Book of Why | Causal Inference in Statistics – A Primer
- Conferences: Causal Learning & Reasoning | Causal AI Conf. | Causal Data Science Conf.
- Companies: Causalens | MarketDial | Mastercard | APT
- Institutions: Standford causal science center |
- Case for causal AI
- Experimentation platform
- Bayesian structural time-series models: paper | R package | R package
- Time based regression
- Synthetic Control Method(SCM): SCM | Generalized SCM
- Statistical Challenges in Online Controlled Experiments: A Review of A/B Testing Methodology
- Many of the AI Decisioning System providers are old school rules system driven by newer incarnations of Rete algorithm: Rete III at FICO and Rete-NT at Sparkling Logic. I hope they live up to Forrester’s definition of the bucket they’re grouped into: AI-Powered, Human-Controlled Digital Decisioning Platforms(DDP).
- ByteDance’s CausalMatch library
- DAGitty, draw and analyze causal diagrams
Notes
[1] I don’t consider the building of a deep neural network from scratch layer by layer with a framework such as PyTorch as science. Any engineer can do it following the abundance of readily available sample implementations. The know-how behind the designing, evaluating and experimenting of custom deep neural architectures is science. And one of the AI/ML Scientist role models I point my daughter to is OpenAI’s Lilian Weng .⤴
[2]You might wonder why I don’t use “correlation” here. Correlation is a special kind of association for quantitative and ordinal data. Since AI is capable of generating multi-modal data such as categorical, imagery or video, the general “association” is more appropriate.⤴