Last updated 4/12/2020 | Personal Opinion
Wouldn’t it be nice if I could swap my DNA with Einstein’s back at school and Jeff Bezos’s now at work? No, I’m not talking about that DNA, I’m talking about Data and Analytics, DnA1.
In this age of explosive data and analytics innovations, vendors or users of analytical solutions alike, we all face the same challenge: how do we architecture our analytic platform or solutions so that they can quickly adapt to changes in data and analytics? Underlying this quest are two common human ethos: anti-rewrite and anti-vendor lock-in (anti-vendor-vendor lock-in for vendors).
Form and Content of Data and Analytics
The variations among data and analytics can be categorized by their physical form of delivery and the logical content embodied in the payload.

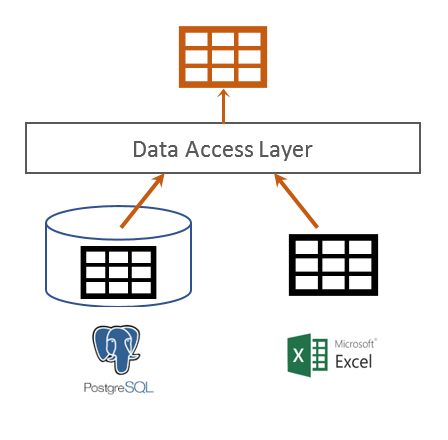
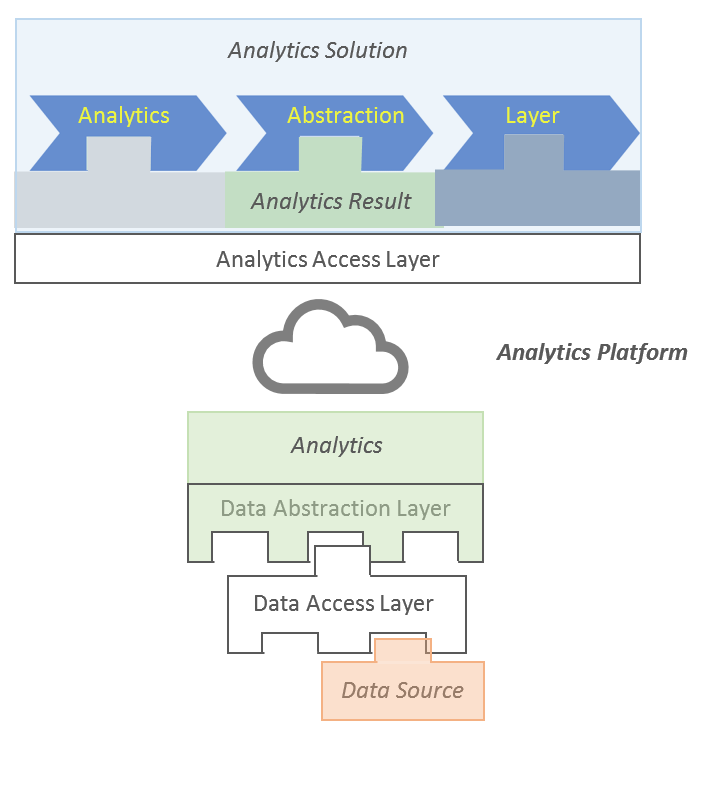
Data Access Layer (DAL)
Data access layer abstracts away the physical difference of data, it loads and extracts data from source and sets them in motion.
If you have a tabular data set such as the iris data, whether it’s in a flat Excel spreadsheet on disk or in a relational database table like PostgreSQL, it’s presented as the same tabular data structure to the upper layers by the data access layer. All the data accessing implementation details such as ODBC or Microsoft Component Object Model (COM) are encapsulated within the DAL and can be interchanged with newer and better technologies, all without disturbing upper level layers.
Data Abstraction Layer (DAL)
Data abstraction layer abstracts away the gap between source and analysis data, it transforms source data into forms and contents that are ready for analysis.
Data abstraction layer implements the data requirement of analytics. For Scikit-Learn machine learning algorithms, two separate ndarrays (for independent and target variables respectively) are expected. For SAS Viya, a single table with all variables are expected. For a complex retail markdown optimization solution, the data requirements might include time series of sales and promotions, as well as merchandise and location hierarchies… Data abstraction layer’s job is to assemble the right data in the right form that’s expected by the analytics.
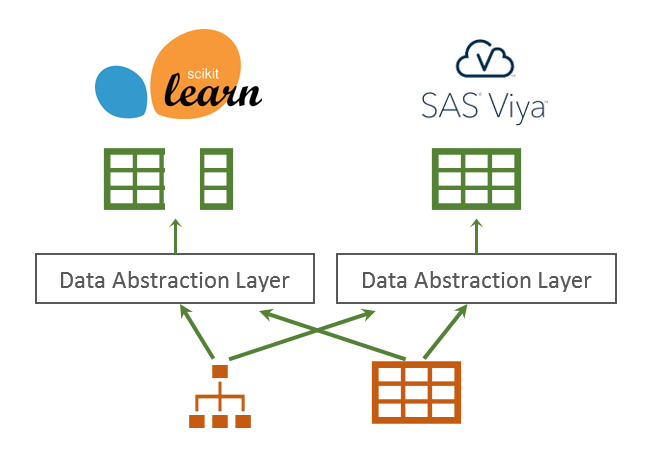
By now you may already get it, data abstraction layer belongs to analytics, multiplexing data with different schemas into the one form expected by the analytics. With the data transformation details (e.g., flattening hierarchical data set into a tabular one, or splitting one tabular data into two) encapsulated in the data abstraction layer, the same analytics can plug and play with different shapes and colors of data, or easily add support for new data, all without disturbing the algorithmic parts of the analytics.
Analytics Access Layer (AAL)
Analytics access layer abstracts away the different ways of delivering analytics to a point of decision.
Although it is possible to deliver analytics as compute, almost all practical applications of analytics consume the result of the analytics by interacting with the analytics’ service API. With details of the form of service (RESTful, gRPC…) and vendor specific APIs encapsulated in the Analytics Access Layer, businesses may build their best-of-breed solutions by cherry picking best tools from different vendors.
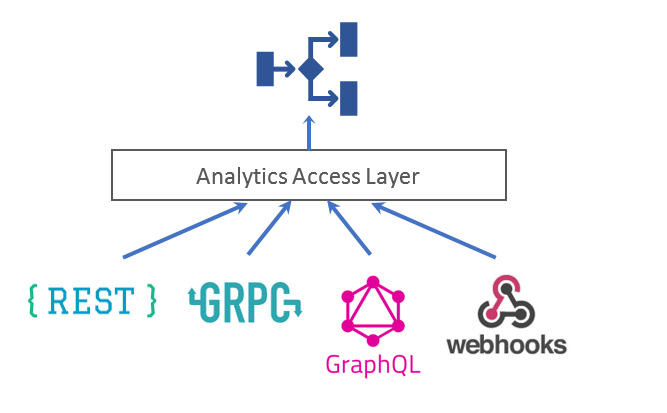
Analytics Abstraction Layer (AAL)
Analytics abstraction layer abstracts away the algorithmic differences of analytics at points of decisions.
Say I have a forecast driven optimization solution, whose effectiveness is defined by the search and decision processes (pipelines). The specific analytics pieces at different decision and search points can be swapped in and out, without disturbing the higher-level search and decision processes (pipelines).
To do the search, I should be able to use any of the available optimization algorithms: Mixed Integer Programming, Branch and Bound heuristics… To do the forecast at each search point, I should be able to use any of the available forecasting algorithms: Winters and Holt, ARIMA, Amazon DeepAR… I should be able to switch them in and out, all without disturbing the upper layer business logic that orchestrates the search and forecast processes.
By separating the upper level domain know-how (business secrete sauce) from the analytics tools, analytics abstraction layer enables the codification of institutional knowledge and fast adoption of analytics advancement.
Putting it Together
By architecting and organizing interchangeable data and analytics components into data access, data abstraction, analytics access and analytics abstraction layers, businesses may focus on the backbone of their analytics platform which remains relatively constant: data and business solutions. The library of data readers, data transformers, analytics accessors and analytics mediators enable reuse across different data/analytic pipelines, application and solutions.
References
- The Database Abstraction Layer is more of an implementation tool for the Data Access Layer we talk about in this blog.
- TIBCO’s Data Abstraction Reference Architecture (bottom of the page) maps nicely to what we talk about in this blog: Physical Layer => Data Access Layer, Application Layer => Data Abstraction Layer. TIBCO’s Business Layer can be thought of an implementation tool for our Data Abstraction Layer.
Notes
- I first heard of the term “DnA” from Blue Cross Blue Shield NC and immediately fell in love with it. Yes, DnA is in my DNA!