As the product owner and the proud brain-father of the internally built Generative AI (GenAI) Gateway, I am inundated with undue enthusiasms and unrealistic expectations for large language models(LLM) from all directions at the same and all times. I found the CRV theorem for LLM formulated below works remarkably well to bring folks to their senses.
CRV Impossibility Triangle theorem for LLMs
The CRV Impossibility Triangle theorem states the following:
At current maturity of GenAI as of 2025, LLM can provide at most two favorables of the following three metrics:
- Cost. How much money it cost you to train, fine-tune and operate the LLMs?
- Responsiveness. How fast you get an answer from LLM endpoints, with respect to user’s expectation?
- Value. How good are the contents generated by LLM, for your use case?
In other words, achieving low cost, low latency, and high quality at the same time with LLMs is impossible.
Or visually with a Venn diagram:
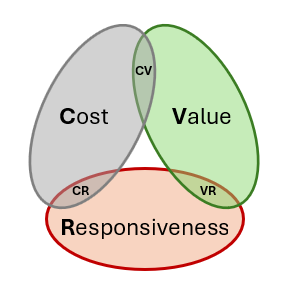
If cost is no issue, you can get valuable contents generated with low latency by:
- Custom train and fine-tune your LLM, by your top-notch GenAI talents, on public as well as your own private data.
- Horizontally scale your LLM endpoint on enough GPU instances to cut latency to your liking.
If responsiveness is no issue, you may still get high values with relatively low cost:
- Construct your GenAI solution in a way such that you appeal to LLM only after other means failed. You searched customer’s question though the whole of your Q&A database at no avail. You Googled for hours on the error message you’re getting without a clue as what’s the root cause… In these situations, users are already conditioned to wait, for anything novel that may point them to a new direction.
Cost-responsiveness-value tradeoffs aside, there are scientific and physical limits to LLMs at their current maturity:
- Scientific limits. No matter how many extra layers of human (RLHF) or algorithmic (COT, Reinforcement learning) coaching put around it, LLM at the core is just a next-token predictor with no understanding. Don’t drink the Kool-Aid of artificial general intelligent(AGI) too early. Rather, lay the LLM fibers to your neighborhood and wait, till it’s truly ready for household level consumption.
- Physical limits. If you expect LLM to respond within one second like all your other APIs do. Do a simple arithmetic operation such as 1 + 1 and repeat it 170 billion times to get an idea the number of computations the LLM needs to carry out. The first ‘L’ in LLM is Large for a reason! Hope is not a course of action. We must live within the limit until new tech (e.g. quantum computing) or new architecture (e.g. Mamba, KAN) extends it.
Advices from me, your cool-headed LLM plumber:
- Focus on value. Quality, novelty, creativity… high value generations not only justify high cost but also reduces if not completely removes the sting caused by the long wait. When the coding LLM pinpoints to the line of my bug and proposes a working fix, I’m more than happy to wait for 10 minutes or more for it.
- Curb your enthusiasm. To previous point, ask how much value-add the generative LLM provides to your use case. If the answer is not much, your money will be well spent squeezing more values out of the old tech. Instead of focusing on the “G” (generation) part of RAG (Retrieval Augmented Generation) pattern, your effort might be better spent on the good old ‘R’ (information retrieval).
Similar theorems in other fields
For non-technical executives, I start talking about the CRV theorem for LLM by drawing the parallel to the R2 theorem for investment which they’re intimately familiar with. For technical stakeholders, I draw the parallel between the CRV theorem and the CAP theorem in distributed computing.
R2 theorem for investment
The risk-return trade-off in investment can be re-casted into the risk-return (R2) theorem:
Any investment vehicle can only provide one favorable of the following properties:
- Risk.
- Return.
Or visually:
CAP theorem for distributed system
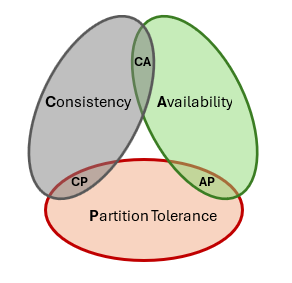
In the field of distributed computing, the CAP theorem states:
Any distributed system can provide only two of the following three guarantees:
- Consistency. Every read receives the most recent write or an error.
- Availability. Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition tolerance. The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
Visually:
Summary
At the core of all these theorems is the tradeoff among a set of conflicting objectives and/or properties. It’s so ubiquitous that we homo sapiens are doing it all the time, intentionally or subconsciously. Have you trade-off-ed today?