The double AI paradigm shifts
On the surface of AI applications, an obvious paradigm shift is happening right before our eyes:
- AI is Power. Who can utilize the new power to the fullest extent who wins.
- AI is being commoditized and becoming utility. Who can secure the most cost efficient provider arrangement who wins.
- It’s often more cost effective to buy from the grid than generating in-house.
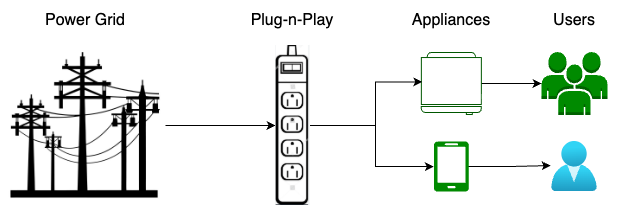
The AI application paradigm shift necessitates pivots in AI practice among pragmatically minded enterprises:
- Shift from model building to model evaluation.
- Shift from AI science to engineering.
- Shift from hype driven POCs to measurement driven adoptions.
Under the hood is the paradigm shift of how AI is built which directly leads to the paradigm shift of how AI is used we just talked about:
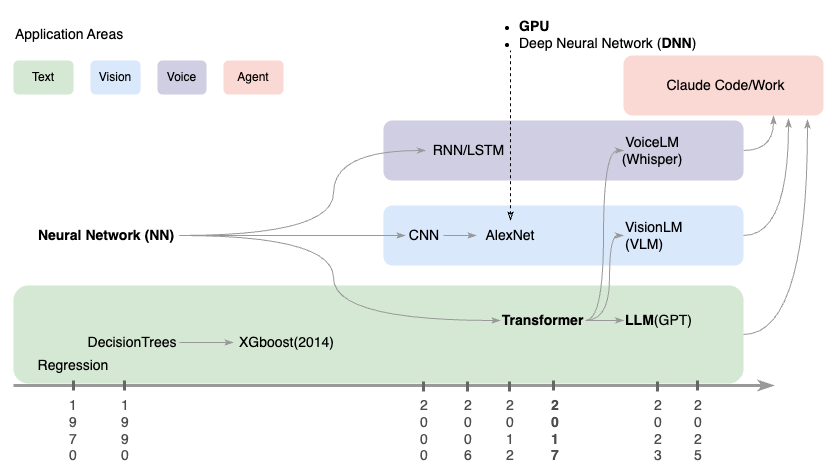
A few comments for those keen to know the technical details:
- Deep Neural Network(DNN) especially the Transformer architecture is eating AI left and right.
- Note that almost all traditional models are effectively discontinued by Transformer models.
- If you have a “scientist” in your title, you must have good reasons why you haven’t built or utilized DNN or Transformer models yet:
- The scare tactic out of the “lack of explainability” claim won’t cut it, as there are no laws or regulations you can point to mandating model explainability at the cost of the super-performance of complex AI models. The best BIS can come up is an unofficial guideline acknowledging the “trade-offs between explainability and model performance, so long as risks are properly assessed and effectively managed”.
- The blame deflection tactic from the “Our company doesn’t have the data” claim won’t cut it, as to the contrary, Your company has tons of private data and with its representation learning capability from raw data DNN models don’t even need feature engineering!
- The scaling law exemplified by the evolution from: (1) the three-layer neural networks to (2) the hundreds-layered million parameters deep neural networks, and finally to (3) nowadays thousands-layers hundreds-billions parameters large language models prohibits small shops from building cutting edge models from scratch.
- The bitter lesson of using general methods that leverage computation is ultimately most effective further concentrates foundational model building into the handful few hyper-AI shops.
The AI supply chain
With more and more of the production models coming from open source or vendors, typical enterprise AI practice is becoming a supply chain:
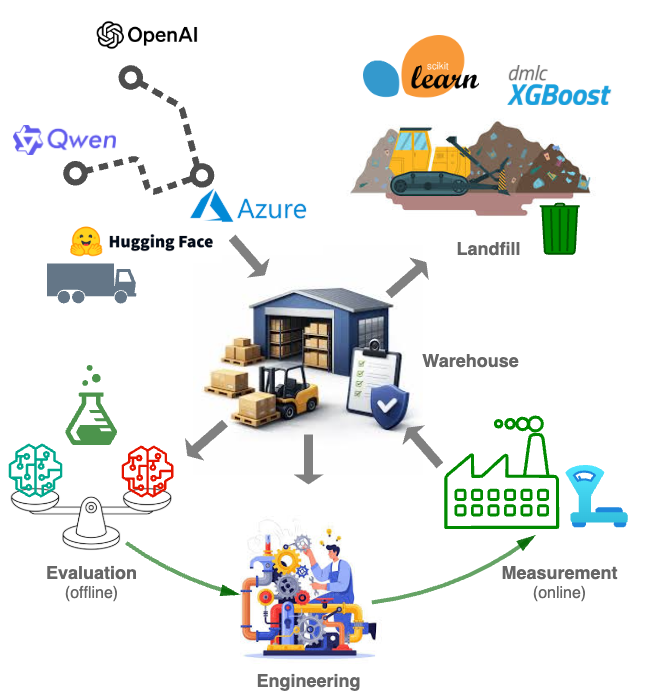
As agile in software engineering lifts tons of inspirations and experiences from manufacturing, the supply chain vantage point of enterprise AI practice enables us to tap in the deep knowledge reservoir of supply chain management.
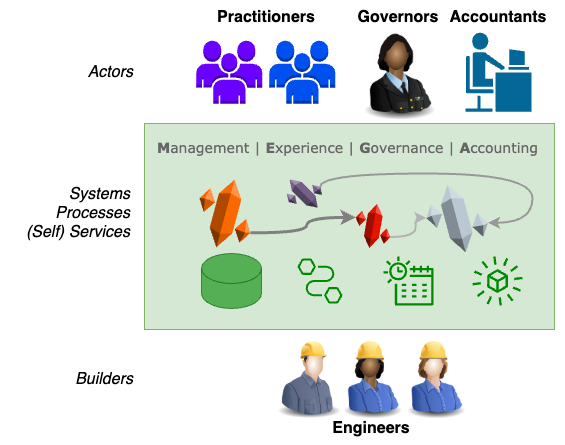
Management, Experience, Governance and Accounting (MEGA)
Cutting across an enterprise’s data, analytics and AI endeavors are four common themes that I nickname MEGA:
- Management, of the assets and services.
- Inventory, ownership and lineage for assets tracking and risk management.
- Components and structure for assets supply chain risk mitigation.
- Services
- Manual services which require human actors.
- Automated services which afford self-service.
- Experience, of the human actors.
- Discoverability of artifacts, actors, processes and more.
- Usability of systems, tools, processes and more.
- Productivity of practitioners, accountants, governors and engineers
- Governance, of the human actions.
- Review to enhance.
- Approval to green light.
- Monitor to ensure.
- Accounting, of the use cases.
- Cost and outcome for profit and loss (P/L) analysis.
Engineering driven
I believe engineering is the key to overcome the MEGA challenges in the data, analytics and AI spaces:
- Manual processes which are repetitive, tedious and error prone can be automated and scaled by software engineering.
- Manual services which are slow and uneven can be offered as self-service, enhancing the experiences of both the service consumers and providers.
- Complex relationships among artifacts, actors and systems can be tracked and made sense of by management information systems.
- Menial grunt work can be automated by AI.
- …
In a word, software should be eating the world of MEGA, not the human actors.
Knowledge powered
The key to efficient management of large scale artifacts and complex relationships among them is categorizing artifacts into much small scale and much more structured categories.
Multi-dimensional
Real life artifacts are always categorized along multiple dimensions, each with its unique hierarchical or more complex structure. For example an AI model:
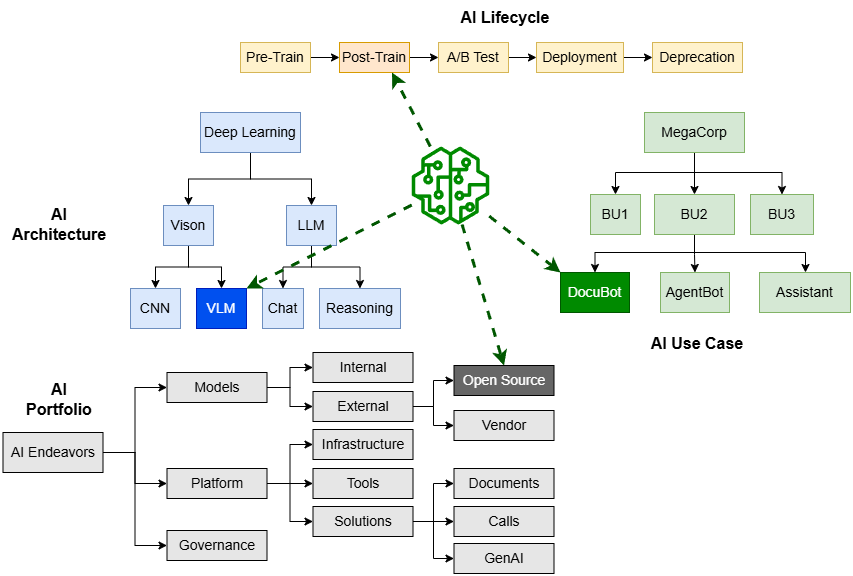
“That looks like a star schema complete with fact and dimension tables!”. You’re exactly right, except the dimensions are not rectangular tables.
Ontology as knowledge
Each of the dimension structure exemplified in previous diagram is a taxonomy, a special kind of ontology. Ontologies and the semantic web stack that’s built on top it is by far the best tool to model knowledge.
As the deities to the mortals, ontologies not only can be used to tag the artifacts but also govern the developments of them.

Domain specific
As a special kind of software, the Data, Analytics and AI (DnA) domain inherits from its parent IT domain the same types of artifacts to manage:
- Assets
- Services
- Portfolios
and the same three goals to achieve:
- Experience
- Governance
- Accounting
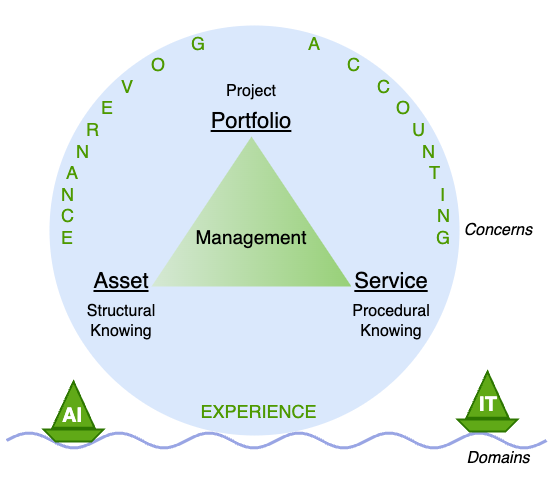
But can off-the-shelf ITAM, ITSM and ITPM software be readily used in the data, analytics and AI domain? The answer is resoundingly No:
- We all hate with passion the horrible user experience of ServiceNow and Jira.
- Then underlying entities and attributes (ontologies) of data, analytics and AI are fundamentally different from those of generic software entities.
- The good-old relational database beneath ServiceNow and Jira is cumbersome to build knowledge driven systems.
- Graph database such as Neo4j is a natural choice to model knowledge graph.
Can the in-house built legacy AI asset and portfolio management systems shoulder the current and future management, experience, governance and accounting challenges of data, analytics and AI? Probably not:
- They’re most likely designed in the same old mold of ServiceNow and JIRA, only on a much smaller scale.
- They focus myopically on one particular type of asset rather than wholistically on all types of assets as well as the relationships among them.
- They most likely lack basic components to be integrated into modern enterprise AI infrastructure. For example:
- On one hand you mandate each request through AI Gateway to be identified with an AI Use Case ID,
- Yet on the other hand your legacy use case management system doesn’t offer an API to do so!
All in all, an opportunity to reimagine and rebuild the whole MEGA system is right in front us. Let’s not squander it!
A reference architecture
To descend from pure hyperboles so far to concrete ideation, I present what a MEGA system may looks like component wise:
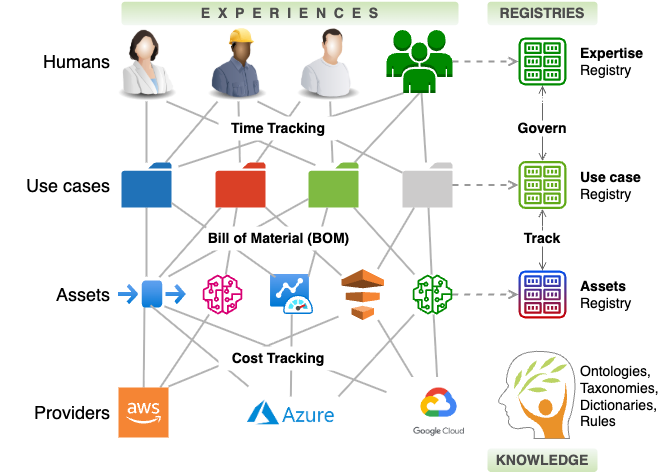
The reference architecture deliberately stays away from implementation details, but to prevent you from reinventing the wheels, consider below existing assets that maybe utilized:
- Service Now the IT Asset Management (ITAM) system maybe used to manage data, analytics and AI assets.
- Back Stage the internal developer portal can be used to manage the software assets for data, analytics, and AI.
An operational model
How to organize and operate MEGA endeavors within an enterprise to the best of its business interests?
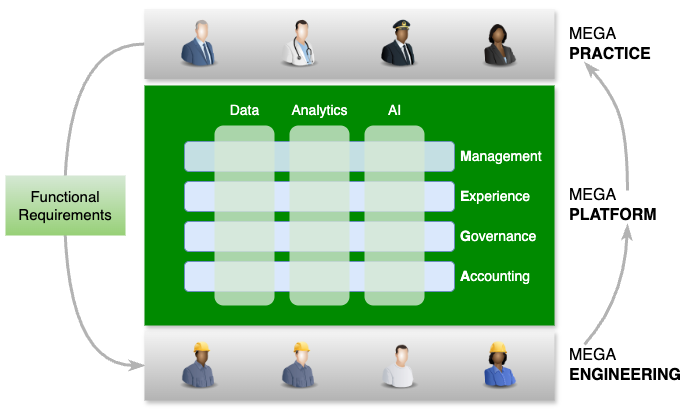
In short:
- Platform vs Practice.
- MEGA the platform affords the functionalities with which MEGA personnel get MEGA things done
- One platform cutting across data, analytics and AI.
- One unified vs three separate MEGA platforms for data, analytics and AI respectively
Miss MEGA
I’ll leave you with Miss MEGA, code name for the set of Management Information Systems (MIS) to tackle the MEGA (Managerial, Experiential, Governing and Accounting) challenges faced by enterprise DnA (data, analytics and AI) communities:
- They’re imbued with knowledge, guarding angles for all aspects of Fidelity business.
- Portfolio taxonomies with the rigor of US Bureau of Labor Statistics Standard Occupational Classification (SOC)
- Upper and lower(domain) ontologies linking data, analytics and AI to business outcomes.
- They’re professionally engineered, with:
- API access to each other as well as other Fidelity systems.
- Workflows and ticketing system with human in the loop for review and approvals.
- Self-services for automated tasks.
- …
- They afford insanely good experiences, for all stake holders at all levels of an enterprise.
I invite you to start thinking about and help to realize this vision at where you work!
